 小序
小序
 小序
小序为了和俊晨的文章成为一个系列,我起了一个自己平日不会用的文章名字。本意是谈谈自适应学习系统的正向作用和可能性,为寄希望于自适应学习系统的同学稍加激励。
因为俊晨上刀剜肉,即使有鞭策的意味,我也看到两类的影响——其中一类反馈说,当然自适应学习系统成不了K12教育的救世主;另一类反馈说,我本来寄希望于自适应学习系统的,但是自适应学习真的如此不堪吗?对于第一类,在救世主层面,教育当然是需要自救,但我们终归不能笼统的驳斥自适应学习系统(我另外一个场合说的,不要指着东施骂西施,这里也适用);而对于第二类,我们当然也需要仔细探讨自适应学习系统的问题,并挖掘未来的可能性,不能一碰到困难就回头。
但客观的说——有朋友也提到这一点,自适应学习系统还处于很早期阶段,打起仗来我们和俊晨们都明白,反方胜在数据说话——“你拿出成功案例来!我们看看数据”,而正方胜在讲故事——“我们基于现在,谈谈下一步”。好在我们正反方的目标都是为了优化教育,而不是为了争胜,这是对话的基础。
先疏通一下概念
我觉得我们双方都有必要谈一谈对基本概念的理解。如果理解有重大偏差的话,我们先不要着急干仗,应该先坐下来,喝茶聊概念。什么时候差不多一致了,再重新挽袖子。
自适应学习,这个概念我们看一些朴素的解释,我这边认可的:
维基百科:Adaptive learning is an educational method which uses computers as interactive teaching devices, and to orchestrate the allocation of human and mediated resources according to the unique needs of each learner. Computers adapt the presentation of educational material according tostudents' learning needs, as indicated by their responses to questions, tasks and experiences.
dreambox有一个简单版本:Adaptive learning is acomputer-based and/or online educational system that modifies the presentation of material in response to student performance.
所以我们在谈的自适应学习,是一种基于计算机的学习模式,这种学习模式的系统,不管是用于教师的教学,还是用于学生的学习,其核心在于使用计算机技术和系统,使得教育素材能够“自适应”于学生的反馈和表现。简单说,自适应学习是通过计算机系统把教育素材和学生自动适配的学习模式。
这是我的理解。
这里面没有限制使用什么模型,也没有限制是什么教育素材,更没有规定具体的场景。俊晨提到了知识图谱,提到了题库和训练,提到了题目推荐,这是因为这即是俊晨的工作领域,同时这一领域在国内足够火爆。在教学场景谈自适应学习,在翻转课堂中谈自适应学习,在MOOC中谈自适应学习——国内在线教育的产品场景更少。
所以,我们选择题目训练及其延展出来的学习和教学场景,来谈自适应学习也没有问题。
这里面,还有一个概念需要先喝茶。也就是知识图谱。这个概念颇为复杂,我先说我自己接触这个概念的经验。
在进入教育行业之前,我在两个相关领域接触过类似概念。首先在NLP/NLU中,早期有一类学者研究(自然语言)语义网的问题,目的是为了让机器理解并处理自然语言,而自然语言的语义又是非常复杂的,包括对人类常识知识的指称刻画——这导致各家语义网的理论核心很精致,但工程上的语义知识库却很粗糙。后来,我们出于信息检索的目的,要构建知识库并做自动问答系统(或叫语义搜索),这个知识工程也称为知识图谱,这其中既包括“刘德华的身高”这种确定性的实体属性知识,以及“刘德华和郭富城都是四大天王成员”这种关联知识,也包括“刘德华哪部电影比较好看?”这种没有标准答案的问题,等等。在研究和挖掘这些知识的过程中,和本体论以及互联网的语义网进行了联合——Google把这个方向叫做Knowledge Graph,国内也就这么叫。这些都涉及了知识网络的概念,但不同于教育领域。
在教育领域,我第一次接触这个概念是我们要做“星空图”——是一种基于课程知识点的网状结构。边代表了知识点之间的关系。后来在和knewton合作接触过程中,我进一步了解到他们基于知识图谱构建的自适应学习系统的原理。而这次借着俊晨的文章,雷达老师提及他对知识图谱的看法,提到了他理解的知识图谱,不仅包括一般性的知识概念网络的层面,还包括教学法知识的层面,包括干预和反馈的策略层面——这无疑大大扩大了知识图谱的概念,整个教育过程中泛指的“知识”,可能都会被纳入。
所以这也是一个非常复杂的概念。当我们说“一个基于知识图谱的自适应训练——或题目推荐系统”的时候,我们需要对知识图谱有一个基本层面的共识,否则我们说的可能不是一件事。
我们先看看knewton对他们的knowledge graph怎么说的[1]:
A knowledge graph is a detailed mapping of educational concepts (learning objectives), based on content, that Knewton’s models can interpret. Using the content inventory, the knowledge graphing team defines these concepts and then determines the relationships between each concept.
在另外一个文档中他们提到:
Knewton Knowledge Graph用语义图示结构展现任意内容。该结构为 Knewton 提供了一种判断学生理解(和误解)程度的方式。
所以我们猜测在knewton中知识图谱就是educational concepts的一种网络结构,这个概念也就是他们设定的learning objectives。这需要专业团队基于内容来进行构建,并可以用于学生理解程度判断和推荐模型。
虽然knewton平台不是一个单纯的自适应训练平台——他们的推荐序列中可以包含教学的过程和内容。但我没有发现这个知识图谱中包括了教学法的知识,以及更多的教学和学习过程中的动态干预策略的知识。
为了减少争议,我优先把知识图谱界定为一个基于课程内容的知识网络结构。我们探讨课程内容的时候,不仅包括了所对应的学科知识,也可以扩展到学科所对应的教育目标,以及教育目标体系下对人的素养要求和支撑性的活动材料(也是内容,但略不同于传统学科的知识体系,允许跨学科知识的素材)。但到此为止。在知识图谱层面,我们不再扩展到教学法等层面。
这可能仍然是不够明确的,在讨论过程中可能出现不易区分的局面——但我们后面再打补丁,否则喝茶的时间就太长了。
挽第一把袖子:互联网推荐与自适应学习推荐的对比以及从反方看正方
俊晨从对比电商推荐和题目推荐开始——虽然俊晨和有关朋友都深刻指出了这两个系统的不同,甚至有朋友说这两个系统不具有可比性。但我们仍然从对比开始,俊晨提到的我们不再阐述,且后面再补充我的对比理由。
我们看这样一个对比的表格:
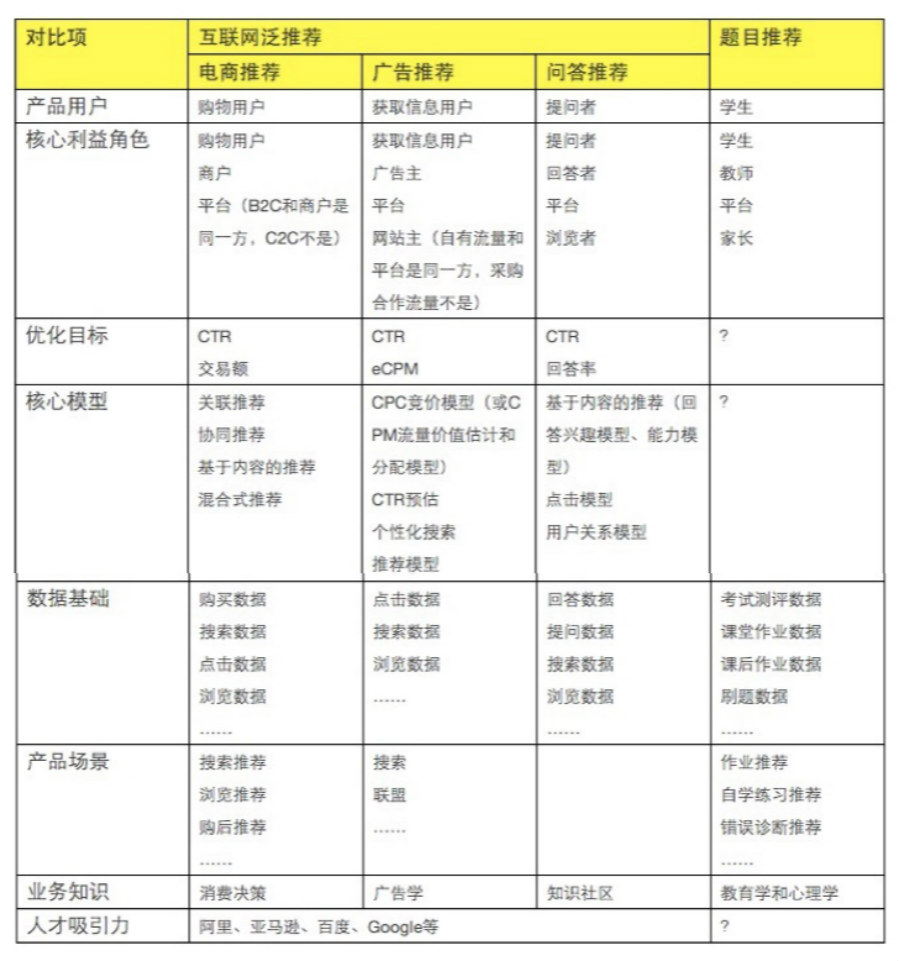
作为进一步聚焦引导,我提示大家从其中三个方面重点来看互联网泛推荐和自适应学习题目推荐的不同:
优化目标:在互联网的多数可行的推荐场景中,系统效果的优化目标都是明确的、客观的,并不依赖于哪家公司哪个团队来实现而不同,也不依赖于具体哪个客户群体。但是,在教育中,即使题目推荐是为了“应试成绩”,应试成绩的衡量标准也不是统一的、客观的,这个优化目标的确定还依赖于实现的团队和具体客户群体,依赖于另一个复杂而工程实践又有诸多问题的教育测评系统。所以现在无论是哪家自适应学习和题目推荐,如果一开始就能建立一个相对客观明确的优化目标并达成全公司一致,这已经是很大苛求。如果没有客观明确的优化目标,系统实现和迭代上会有非常大的技术问题;如果没有统一认可的优化目标,后面公司管理和资源调度时会有非常大的管理问题。
数据基础:在互联网所有商用的推荐场景中,互联网都有着巨大的数据基础,互联网的流量、用户量以及核心行为量都是海量数据,且经过了长期的质量优化。无论是大数据还是人工智能的技术火爆性,都是发端于互联网行业。但在教育行业中,数据基础是非常薄弱的。所有亲身经历模型项目的人都知道数据的重要性,但在教育行业,有效的数据收集还在逐步进行中,而且,教育的主战场——学校和课堂,有大量的数据目前是难于收集和标准化的。这导致我们如果通过数据来观测教育系统,训练自适应学习,那真的是管中窥豹——通过一个斑点来预见豹的速度吗?
人才吸引力:我们只看两份数据就知道,大数据和人工智能人才,每年的优秀毕业生有多少进入互联网行业,有多少进入在线教育行业;从业人员的薪酬水平,两个行业的对比情况如何。这些数字不需要列出大家也能感受到对比情况。
所以自适应学习题目推荐和互联网泛推荐相比,差距是全方位的——不仅仅是解决的问题本身,以及模型方案的深度和有效性。
如果从反方看正方,某些同学可能感受到对自适应学习的更加深深的沮丧——但这就是现实,这个现实在我的观念中,那就是,自适应学习系统还处于发展的早期阶段,和它的理想状态相比还是开荒的时间。
这就是我对比的理由,如果要对比,一定要提出结论之一,互联网泛推荐已经进入青壮年,而自适应学习系统还处于咿呀学语的婴幼年。
挽第二把袖子:让我们仔细看看怀里的这个孩子
让我们轻轻的揽住这个孩子,它的眼睛还微闭、臂膀还像藕节、肢体还非常的稚嫩,它不能谈笑风生、妙语连篇,它不能快如闪电、雷厉风行。它还是一个孩子,但它未来有无限的可能。
它能让我们从理解学生的视角,来看待教育的内容。我们的课程,知识,活动,我们所有的教学内容和教学活动,不仅需要从教学视角去看,还更加需要从学生的视角去看,从学生的内在发展规律去看,我们的课程计划应该是怎样的,知识的理解和迁移是怎样的,活动的支撑和实施是怎样的——我们为了把课程、知识和活动通过计算机自适应的匹配给学生,势必会深刻影响我们对内容的认知和析构方式。
它能让我们从理解课程知识的视角,来看待学生的发展。学生在发展过程中既有一定的规律,又有可塑性和发展的潜能。人类千百年来已经实践出足够海量的知识和能力范式,而且时至今日仍然在快速叠加。如果把青少年时期人类的成长任务之一定位为接受这些知识并发展出能力范式,我相信没有任何人知道这对我们的学生意味着什么——我们迫切的需要深刻的知道我们海量知识和能力范式的内在结构和规律,并用它来建构和支撑我们学生的成长。这种塑造我称之为成就学生最大可能。
它能让我们从对方回看自己的方式,来看待课程教学和学生发展这两端所形成的系统,并用实证的方式,用计算机和人工智能的方式,用教育技术的方式来加速系统的发展。它必将带来一种全新的学习和生活方式。
有的朋友可能会说,你这碗鸡汤炖的不是鸡。我说,自适应学习这只鸡,未来有变凤凰的可能。自适应学习的彻底研究,将会驱动我们深刻改变人类学习和成长这件事。所有纯人类主导的成长,都可以是一个黑盒方式,我们不知道孔子带着弟子们周游列国发生了什么,我们不知道阳明先生龙场悟道发生了什么,但自适应学习将驱动我们用一个白盒的视角,去解构这一切[2]。
可能不会成功。是的,可能是如此。
但谁能阻止一个怀里抱着孩子,做梦的父亲或母亲呢?
挽第三把袖子:我们来帮帮孩子,跨越婴幼年的困难
我平和一下感情,聊聊自适应学习的困难这件事。先给一张旧的大图: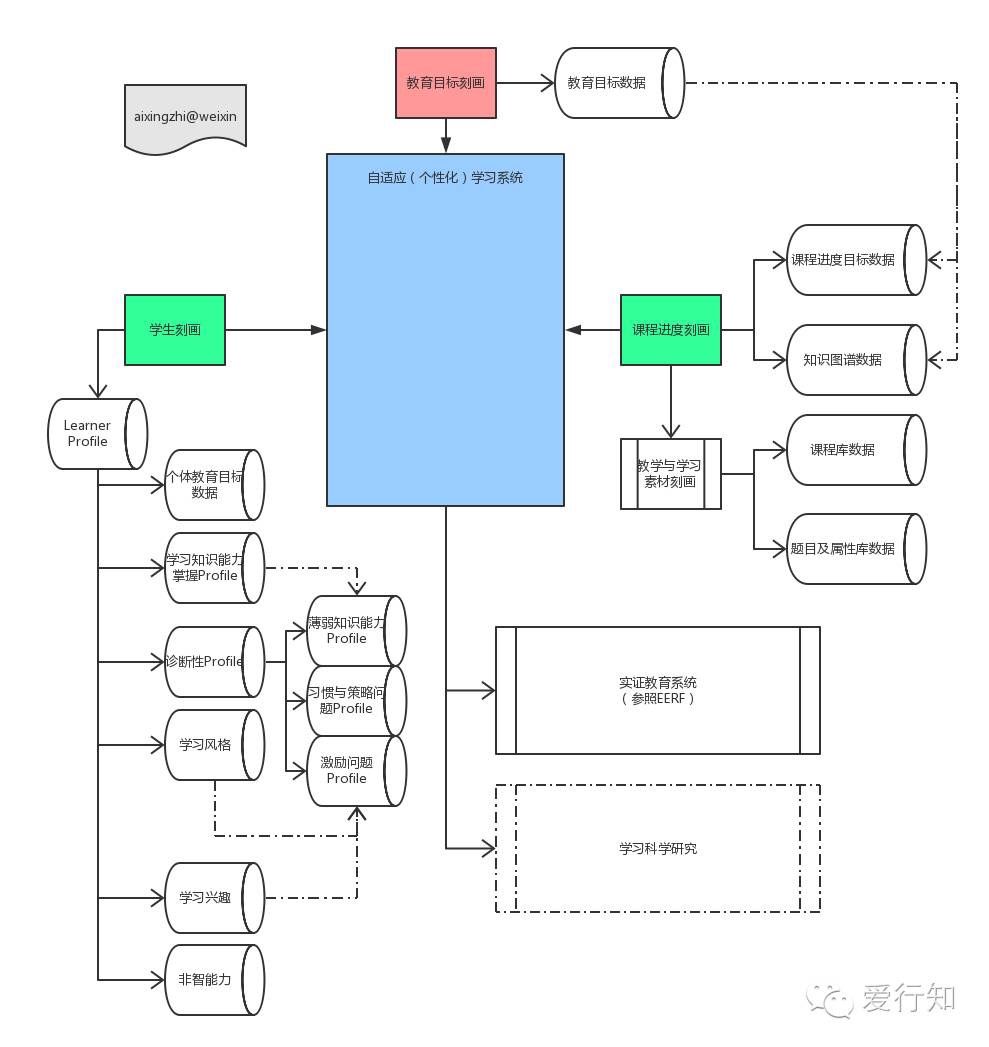
这张图,是用自适应学习系统来达到个性化学习的目的,这样的一张架构图。在这张图中,指出了一个婴幼儿的自适应学习系统,它最重要的三块基石:
第一块就是教育目标刻画和课程进度刻画。这是教育的目标和内容(包括教学内容和训练内容等)。
第二块就是学生的学习刻画,包括个体的教育目标,以及从数据和系统角度对教育测评的拆解。
第三块就是实证教育系统的实施和学习科学的研究,不断在学习过程中具体的问题层面进行研究和优化。
这三块我们之前一系列的文章中,都在不同层面探讨过。对于教育目标、教材课程,在《李子谈基础教育与技术》中有一部分,对于建构课堂的内容库搭建例子,和教育测评,在《教育测量与评价初步》中有一部分。
我们今天先泛泛的说,如果志在做一个自适应学习系统,那么必须在这三块有优势或者优势合作伙伴,即:
在中国纲本并重的情况下,认真[3]的去研究国家课标,研究主流的教材版本,研究有丰富经验教师的课堂案例,并从其中认真的建设教育目标数据和课程进度数据,题库的题目要认真研究它的质量,对教育目标和课程数据的吻合程度,要认真投入这件事,或者找到认真投入这件事的合作伙伴;
在中国教育和学生发展不平衡的情况下,认真的去研究学生刻画和测评,并进一步筛选出自己合适服务的对象;如果自己教育测评的能力薄弱,一定要找到合适的教育测评合作伙伴。面向这些对象,进一步明确问题和数据刻画维度,从自己可以开始的对方、擅长的地方开始;
自适应学习系统要多找参照,进行效果方面的数据分析和实证研究,对学习过程及其策略要不断的去迭代。
如果这些都准备做了,才是真的准备去做自适应学习系统。那么我们再来看两组问题。
第一组是我挽第一把袖子中重点聚焦的三个问题:
问题一是优化目标的问题。这的确是一个极大的问题。但实际上可以通过两个方式来降低门槛,其一是研究教育目标和课程的能力,这一点无论如何不能弱(弱了的话本身就做不了学习模式的创新),有了高质量的教育目标和课程进度的数据,即使是对孩子学习行为和结果的简单统计,也是非常有用的;其二,有意识的寻找专业的教育测评的合作伙伴,结伴前行。优化目标不是一下子就可以解决的,要有前行的耐心和耐力。
问题二是数据基础的问题。这在运营和工程上都有很大的挑战。但我们仍然注意到,一些公司在收集关键数据的节点上进行发力。随着教育技术的发展,数据收集的问题只会越来越容易。
问题三是人才吸引力的问题。除了行业发展和老板格局之外,我们可以从另外一个视角来看,那就是,真正有创造力、喜欢挑战的人,一定不喜欢一个百分之八十问题都有固定解法的世界。开荒的世界适合开荒的人!来吧,这里有百分之八十的问题都需要发挥你的创造性,按照固定节奏升职又有什么意思?!
第二组是俊晨提到的一些问题。
首先是现实残酷的两大原因,其一是固定的教学计划对个人的发展节奏限制太严重。我认为这个问题会越来越被打破——不仅西方教改的潮流,创新学校的探索方向,即使中国的学校,开始学习并探索选修课程体系,探索AP课程的时候,这个问题都在逐渐的缓解。其二是我们对学习过程的理解太浅薄,止于测评,没有深入到教学。我相信这只是在线教育公司的一个现状,会有更多的公司深入课程和教学,会有更专业的公司深入做测评,泥沙俱下,终会淘金。比如说,我就是一个转向教学的人^_^。
其次,俊晨提到基于知识图谱的自适应学习系统,相对传统教辅的用处有:减少刷题量,明确刷题优先级,知识点的掌握程度的定量测评。俊晨大胆猜测从提分角度来看,应该是然并卵。但我认为,对于降低刷题量而言,从高一到高三整个学习过程来看,对于学中和学弱还是有意义的,一方面不要浪费时间,一方面不要打击信心。对于没有教学干预而提分的天花板问题,自适应学习系统完全可以探索教师使用的产品场景和模式。对于学生不愿意学的动机问题,我们固然解决不了所有的动机问题,但持续的挫败感积累所导致的学生信心崩溃的问题——自适应恰恰是可以解决的,如果再辅之以教师认可的学生个体教育目标下来看的视角,学生不太会出现持续挫败感[4]。
这一组问题,再深入一些有两个点会超出我们的讨论范围,需要改天另聊。第一个是什么样的自适应学习系统可以适合教师教学的部分场景和环节来使用——我相信是存在这个场景和环节的,但这里不再深入。第二个点是学生的学习动机问题。这是一个非常复杂的问题,当然远远不是自适应学习自身所能完全解决的——但如果一个学生的学习动机发生危机,他厌学了,那么所有的教育模式都会出现问题,不仅仅是自适应学习会出现问题。学生已经到了教育的悬崖边上,所以也得另外单独来谈。
所以俊晨笼统的把学习数据要分析和解决的问题,划分为下面三个:
学生现在学成什么样子?
学生是怎么学的?
老师是怎么教的?
我们不管互联网的泛推荐的内部机理是怎样的——事实上那个已经远比自适应学习更清楚了。就上面这三个问题而言,我相信对于相应的学科:
教育测量与评价
学习科学
课程论与教学原理、教学法
都不会裹足不前。
只要孩子的教育问题和学习问题仍然存在!只要我们仍然期望给孩子提供更好的教育和学习支撑!只要我们对基于计算机的学习模式还抱有信念和信心!那么,自适应学习系统就会随着众多学科的发展,随着在线教育的发展而继续发展。
作为这个系列暂时的结束,我端上俊晨给大家的鸡汤:
路漫漫其修远兮,吾将上下而求索。
——适合干且愿意干的同学,干了吧。
附录
我简单说一下我了解的国内行业业态。
一部分语言学习的产品和工具(以英语为主)具有一定的自适应学习系统的实践。这是因为英语学习的课程材料足够丰富,标准化的测评比较成熟,题库的数据也足够多。而且,客观题为主,数据收集难度较低;即使是语音测评,也因为人工智能技术的发展,而有了模型的商业化版本。
另一部分,就是进入公立校的各种以题库为基础的公司,比如作业工具,比如过程性评价工具,部分组卷功工具等等。他们能够收集一部分学习数据,并基于此做一部分自适应学习系统的探索。以俊晨所给出的方案思路为主。也存在我们探讨的各种问题。
再有一部分,会有一些公司以核心节点切入,现在做一些准备工作——比如,切入公立学校做考试数据采集和分析,优先进行大规模的数据收集和学生的认知工作。后面会深入到自适应学习系统中来。(这一类我们没有算独立的测评公司,我们都不确认他们做好测评之后会不会切自适应学习系统——如果他们考虑做形成性评价,应该说极有可能会切。但现在这个时间点来看一切都还早)
还有一部分,有一些创新者会选择一个自己认定的切入点,进行业务和系统创新;广泛意义上也是自适应学习系统的探索。如针对学习诊断性的需求,搭建更好的诊断性相适应的知识结构和题库,如针对学弱学中的学生的需求,来搭建自适应训练系统(还会结合游戏化的思路来激励),等等。如果有投资人想进一步了解,我可以把创始人介绍给你们。(给公众号发信息即可)
至于我自己,如果没有特殊机缘,会优先投入到课程体系和教学中,把教育目标和课程体系实践到一定程度,自然会回过头来看形成性评价和自适应学习系统。大概就是这样子。
未来基于全新的教育目标、课程体系和教学场景,基于全新的学习任务设计,基于进一步的实践,我可以再具体谈一谈自适应学习系统。
[1]摘自knewton的部分未授权公开的文档,所以仅做概念描述,不会扩散任何文档更多细节内容。欢迎大家前往knewton官方网站寻求支持与合作。
[2]我们可以看教授主义的课堂,也可以看建构主义的课堂,可以看机械的学习,理解的学习,精熟学习,也可以看基于问题的学习、基于项目的学习、协作式学习、探究式学习,乃至个性化学习——等等,只有自适应学习才是基于计算机的学习模式。
[3]之所这里标黑这么多“认真”的修饰词,就是为了说明一个问题:“互联网+”模式不是“垃圾场+”模式。这也是今天讲故事过程中唯一针对案例和数据来说的话:大部分基于题库的自适应学习系统,其题库和题目质量真的值得review。举一个业内最常见的例子,最有教研能力的人做架构和管理,次有教研能力的人做流程和终审,再次的做初审,再再次的做编辑,然后雇一堆大学生做试题采集、录入和部分编辑工作(或者直接蜘蛛扒题目数据),用这种方式做百万题库,然后我们学生一辈子也做不了一百万道题目——这就是我们最典型的题库建设方式。以后楼盖的再花哨,可是也改变不了地基是一堆狗屎的事实。
[4]有朋友会质疑个体教育目标对于学弱的意义——既然都是已经要放弃了的,降低一点当前的教学目标又有什么问题?人本来的不同,就可以设定暂时不同的当前教学目标。让他看到进步,而不是对统一目标的差距,有时是有好处的。当然,如果说问题是老师是否会这么做——那这是教学实施的另外一个问题,会有更多的老师能够做。
本文转载自爱行知,作者李子。