
芥末堆 红印儿 12月20日
“当你吃完一块蛋糕,想再找一块与之相似或者完全不同的蛋糕时,光靠蛋糕名字是很难进行判断的。”考拉阅读创始人兼CEO赵梓淳说,“你需要知道蛋糕里面都有哪些原料、原料配比如何,才能进行比较和选择。”
这个情况也适用于儿童阅读。2016年,全国共出版少年儿童读物43639种,图书种数比2015年增长19.12%。面对浩如烟海的书目,想在最短的时间里找到自己喜欢的读物并非易事。尤其当儿童还不够了解自身的阅读能力水平时,选择适合自己的阅读内容就变得难上加难。
考拉阅读希望用中文分级阅读产品为K12学生提供适合的阅读内容。赵梓淳从两个方面来解释“适合”的意思,“一方面是孩子看得懂,也就是文本难度适合;另一方面是孩子感兴趣,也就是内容适合。”
细化内容颗粒度,用分级阅读标准量化文本难易度
要想给学生提供适宜的阅读内容,考拉阅读需要一套能够同时测量文本难度与学生阅读能力的标准,进而将学生与适宜难度的文本匹配起来。
实际上,英语分级阅读中已有较为成熟的分级量化文本难度和读者阅读能力的做法,例如覆盖美国50个州的蓝思分级体系。蓝思分级阅读测评体系主要从词频和句长来判别文本的难度。但由于中文独有的一些特点,这两个判别维度都不完全奏效,考拉阅读团队需要对测量标准做很多特殊处理。
比如,中文里的一些低频词其实并不会过多影响读者理解文本的意思。 “‘鬣狗’这个词不常见,‘鬣’的字形还很复杂。但当‘鬣狗’两个字作为一个词出现时,不认识‘鬣’字也不会影响阅读理解。” 赵梓淳说,“所以不能单以词频来判断中文文本的难度。”

考拉阅读建立的中文分级语料库
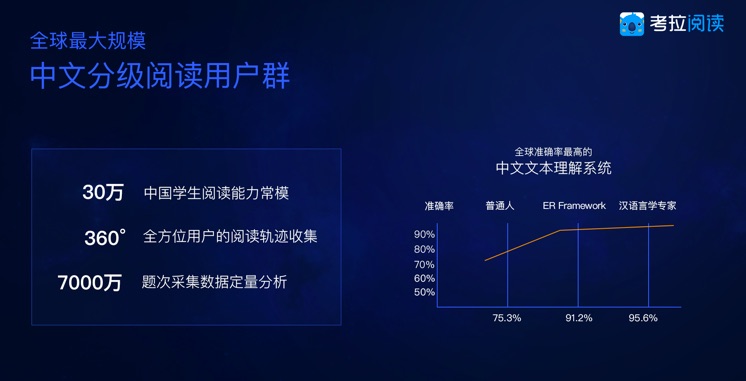
文本难度与阅读能力测量是一项集统计学、语言学、数据挖掘、人工智能技术、心理学等多领域知识与应用于一体的工作。考拉阅读团队处理了1300万字非平衡语料库,近两亿字平衡语料库,最后搭建出名为“ER Framework”的中文分级测量标准。该标准可以测量出任一中文文本的难易度或任一学生的阅读能力,以200ER-1300ER为难度区间,数值越大,文本难度或是阅读能力就越高。
基于ER Framework的测量结果,考拉阅读的系统会自动为学生推荐难度适宜的图书,学生也可以自主选择与自己阅读能力相匹配的图书。考拉阅读还在通过“图书基因组计划”对文本内容做更加精细的解剖。“例如,如果可以计算出某本书有3%的恐怖元素,另一本书的大部分内容都跟圣诞节有关,就可以进一步优化图书推荐的算法。”赵梓淳说。
扫描学生阅读能力,辅之精细化运营
测量出学生的阅读能力是向学生推荐阅读内容的另一前提。考拉阅读的阅读能力测评涵盖五大维度,对最基本的信息提取能力到较为高级的实际运用能力均有考察。
为了让测试结果更加容易理解,考拉阅读将ER值与学生在小学一年级到高中十二年级之间的阅读能力对应起来。一年级到十二年级的阅读能力按照年级被分十二级,再按学生在该年级的就读时长做进一步细分。“比如,‘5.1’就代表五年级学生在读完五年级第一个月之后的阅读能力水平。”赵梓淳解释。
阅读能力测评标准基于学生的海量数据建立。截至2017年11月,考拉阅读联合教育部基础教育质量监测中心和国家语委汉语智能教育中心采集了全国三十余万K12学生的阅读能力信息,继而打磨出学生的阅读能力量表和常模。
考拉阅读建立的中文分级阅读测量体系
不过,不同经济发展水平地区的同年级学生阅读能力差异不小。例如,北京中关村某小学三年级学生的阅读水平可以达到5.5,而甘肃省某乡镇小学三年级学生的阅读水平却只有1.6。因此,同一常模与量表在不同地区并不完全通用。“接下来我们想把常模做得更细。”赵梓淳说,“比如分别制作华东、华北、西北分区的量表。”
诊断出学生的阅读水平之后,考拉阅读会向学生推荐适合的阅读材料。“我们就像今日头条那样做推送,但推送不仅仅是基于学生的兴趣。”赵梓淳说。考拉阅读推送的阅读内容包括自主研发的短篇阅读、新课标书目、儿童图书大奖获奖作品、京东和当当的畅销书等。
即便是同样的文本,不同阅读能力的学生看到的文本标签也会有所不同。“比如曹文轩的《草房子》这本书,一些学生看到的图书标签是‘小菜一碟’,另一些学生可能会看到‘适宜阅读’的标签,还有一些学生看到的标签可能是‘值得挑战’。”赵梓淳说,“每个孩子看到的都是不一样的东西。”
推送自适应的阅读内容只是考拉阅读发力语文自适应学习的第一步。相较于英语、数学,语文辅导与学习的效率通常不高。“语文的知识点不容易被串成线,只靠死记硬背的话,学生容易丧失兴趣,学习效果也没太大提高。”赵梓淳说。考拉阅读希望通过个性化的学习内容让语文整体能力提升的过程更有效且更可视。
B端与C端齐头并进,瞄准语文自适应学习
学校是考拉阅读推进语文自适应学习的一个切入口。由于分级阅读理念在国内的认知度尚未很高,考拉阅读的推广过程其实也是教育市场的过程。“刚开始我们总是去讲分级阅读的各种理论和测量方法,发现学校老师并不理解。”赵梓淳回忆,“后来我们就改为现场展示如何测量文本难度。大家亲眼看到测试结果,就慢慢信服了。”
老师是考拉阅读B端服务的主要使用者。“以前老师可能只是给学生分配几本阶梯阅读训练书,现在通过考拉阅读的系统,老师从终端上可以一键完成分发,把更具针对性的阅读内容推送到学生的设备上。”赵梓淳介绍,“这些分级阅读内容就像是数据驱动的教辅材料。”

考拉阅读教师端效果图
除了发放分级阅读内容,考拉阅读还配套提供文本的导读、思维导图及测试题,便于老师与学生进行更多的互动,并同时追踪实际的阅读效果。另外,老师还可以在后台看到学生学习与使用数据的分析结果。
这些数据不仅便于老师更有效地安排教育计划,还为考拉阅读优化整个分级系统提供支持。“从B端回收的数据往往质量更高。”赵梓淳说,“C端的数据则可能不够‘干净’,比如学生的玩耍时间可能也会被计入阅读时长。”
得到学校和老师的接受为考拉阅读提升C端用户的认可度奠定了基础。目前,考拉阅读还有小部分的海外用户。“一些海外用户是教中文的老师。”赵梓淳说,“主要是为了解决当地缺乏母语学习环境的问题。”随着AI技术的成熟与市场认知度的提升,赵梓淳相信C端用户会越来越多。
考拉阅读于12月5日宣布完成近千万美金A轮融资,资金将主要用于累积底层AI技术,打造“人工智能+阅读”研究院XY Research,并逐步发力C端市场。